

There are many times when it may be helpful for a bot to stop until a prerequisite condition is met and then restarted at the point where the bot exited. Examples where this may useful include waiting for an overnight job to run successfully, executing a remote task to run on another system closer to the data or processes more quickly, or optimizing time and efficiency in attended mode operations.
Effective bot design can significantly improve your bot utilization. Polling and wait operations will limit the availability of the Automation Anywhere Bot Runner to execute other bots that are queued to run. Automation Anywhere provides multiple mechanisms to help optimize bot efficiency in tandem with good bot design.
The first and most effective way to ensure the bot is not stalled waiting for an event to occur is to use triggers. Triggers run bots when a condition is met. For example, appearance of a file in a folder. When the conditions of the trigger are met, the associated bot will be executed.
If the wait condition happens in the middle of a process, driving efficiency may be a little more complex. If you can break the process into discrete steps then perhaps you can eliminate the need to wait by capturing those steps inside of a bot that is linked to a trigger. If this is not possible, then you will want to design your bot so that it is not taking up valuable Bot Runner time waiting by creating a state machine.
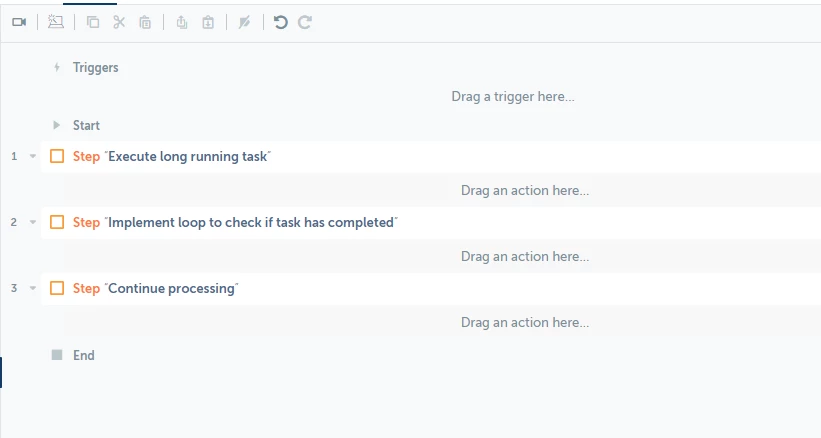
Figure 1: Bot will block all other bots until condition is met
A state machine is a bot that executes differently depending upon a set of conditions. Lets assume that the long running task executes some steps and then waits for something to occur before it can continue. In this case you have three states: start, waiting, and continue. Start state is the state the bot is in when it runs the first time. When the bot hits the point in the tasks where it would stop an wait, you can introduce a condition, such as checking a file in the file system or reading data in a database. The key here is that the bot does not “block” – stop and wait—but it is dependent on coordination with the task it is waiting to complete to generate some signal.
Now, instead of designing your bot to be a set of sequential steps, your bot will immediately check what state it is in and execute the steps in the bot encapsulated in that state’s step block.
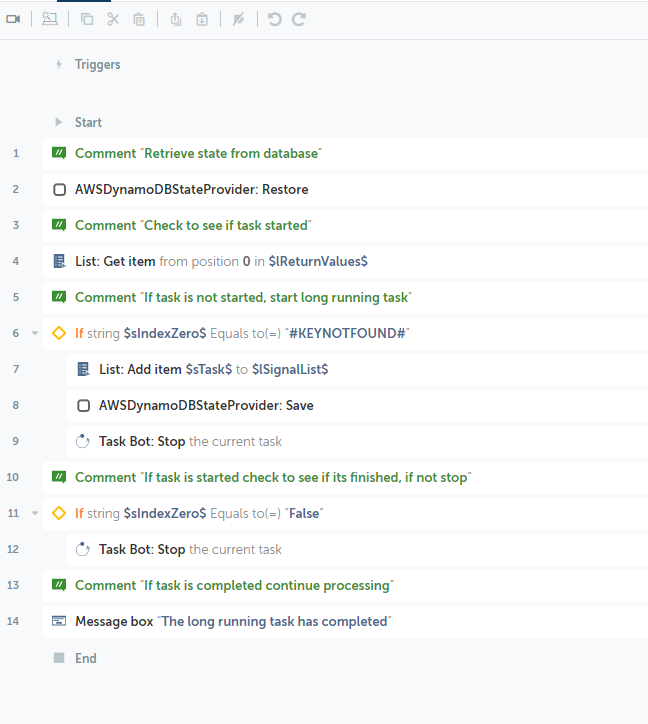
Figure 2: Example of state machine bot
This bot uses a command to save and restore state to a database. The first thing we do is attempt to restore the state relative to this bot. If there is are no entries in the database yet then we know we need to kick off the long running task. Notice, immediately after we start the task we stop the bot. The assumption is when the other task ends it will update the state in the database signaling to this bot that it can continue. There’s a few ways this bot can be used, let’s look at both an unattended and attended example:
- Unattended mode example – we will schedule this bot to run every 10 minutes. Since the bot only uses minimal bot runner time if the other task is still running, it will free up time for the control room to schedule the next bot to run. If we use a device pool, the bot can be scheduled on different devices each time with no dependencies to previous runs. Moreover, many customers have bots that are dependent upon overnight batch jobs running successfully. When this doesn’t occur, it can sometimes result in a domino effect. Enabling the bot to wait for the signal from the batch process will minimize the potential for rework.
- Attended mode example– consider a call center or support agent that is assisting multiple people simultaneously. While the agent is assisting customer 1 they may require a bot to perform a lengthy task of collecting data or awaiting manager approval before continuing. This method would notify that the job was submitted and terminate the current instance of the bot allowing them to put the customer on hold, while they move to customer 2. When the job is complete and they execute the bot for customer 1, it will pick up where they left off.
In addition to optimizing the use of bot runners, this design model has the additional value of being more resilient. If the bot should fail for any reason, this bot design also can be used to limit the need to perform cleanup tasks or start from scratch. In this case, I use a List variable to save and restore state. If you maintain your variables in a list like this and save a specific checkpoints, a bot can resume its operation at the most appropriate point.
